Torne-se MEMBRO VIP
E tenha acesso a todo o conteúdo do fórum e os downloads ilimitados.
Quero ser VIP

rockcavera
-
Posts
374 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Everything posted by rockcavera
-
@Jimmy, você teria que pensar nos possíveis problemas jurídicos que poderia ter pelo fato de transformar o forum em um "serviço" propriamente dito, independente de visar ou não lucro. Claro que da forma atual também pode acabar sofrendo algum processo, mas ao tornar um serviço, a chance de se judicializar algo contra o forum e o seu proprietário aumentam, pois o forum vai ser visto dentro da lei do código de defesa do consumidor e tudo que implica. Exemplo: algum usuário publica um programa maliciosa, um assinante do forum baixa e tem prejuízo com isso. O forum acaba sendo parte legitima. Não que não possa ser no modelo atual, mas é mais difícil alguém entrar com um processo contra um forum aberto, grátis. No caso de um forum pago, as pessoas, pela insatisfação, podem externar em um processo judicial de forma mais fácil, ainda mais coma facilidade de se entrar com processos de pequenas causas sem advogado. São várias coisas a serem pensadas e uma acessória jurídica e contábil teriam que ser vistas para te passar o que pode e não pode ser feito, o que você pode ser responsável ou não... a forma empresarial mais adequada aos seus riscos... Agora, tirando essa parte mais jurídica, vou falar o que EU ACHO. 1) ao tornar o forum SELECIONADO, apenas para assinantes e para os vips, etc. pode haver uma perda de conteúdo de pessoas que querem expor algo que encontraram e não estão afim de assinar o forum apenas para expor sua ideia. 2) as discussões do forum vão acabar se polarizando em determinadas pessoas até que elas deixem o forum. 3) talvez o forum perca a sua essência, que ao meu ver, é ser o maior forum de discussão sobre loterias do Brasil. Poderá ser o maior forum privado de discussão de loterias do país. Além disso, eu sou um apreciador do opensource e do uso livre de softwares. Claro que nem sempre dá para deixarmos algo exposto para todos, pois podem se aproveitar disso para fazer dinheiro as nossas custas (algo que parece ocorrer aqui no forum com aproveitadores que pegam ideias aqui e lucram em seus canais, sites), até por isso os meus programas são gratuitos, mas código fechado, pois há diversos sites, brasileiros e gringos, que faturam horrores com programas lotéricos de qualidade duvidosa. No entanto, possuo um repositório no github com vários projetos de código aberto. Mas a decisão, meu caro @Jimmy, só cabe a você. Você precisa saber o que vale a pena para ti, pois quem mantem é você. Só você sabe o valor sentimental que tudo isso tem.
-
[OPINIÃO] O que precisa ter no fórum para melhorar?
rockcavera replied to Jimmy's topic in Notícias do Fórum
Isso vai contra a lei. É exploração de jogo de azar. O forum poderia ter problemas legais. -
Quem você acha que merece ser Super VIP e ainda não é?
rockcavera replied to Jimmy's topic in Notícias do Fórum
Voto no @AFAS e no @Wata -
Fórum OFF, mas estamos de volta. Reporte aqui qualquer problema!
rockcavera replied to Jimmy's topic in Notícias do Fórum
Boa noite, @Jimmy. Caso queira uma fonte que todos os caracteres tenham o mesmo tamanho, será necessário aplicar uma fonte monoespaçada. Existem várias opções legais. Abraço. -
Version 1.0.0
57 downloads
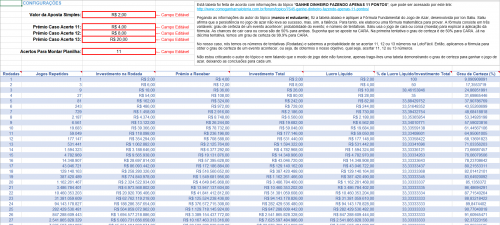
Está tabela foi feita de acordo com informações do tópico "GANHE DINHEIRO FAZENDO APENAS 11 PONTOS", que pode ser acessado por este link: http://www.comoganharnaloteria.com.br/forum/topico/7645-ganhe-dinheiro-fazendo-apenas-11-pontos/ Pegando as informações do autor do tópico (marcio el estudante), fiz a tabela abaixo e apliquei a Fórmula Fundamental do Jogo de Azar, desenvolvida por Ion Saliu. Saliu afirma que a persistência no jogo de azar não leva ao sucesso, mas, sim, a falência. Para tanto, ele elaborou uma fórmula matemática para provar. A fórmula consiste em três variáveis: grau de certeza de um evento acontecer; probabilidade do evento; e número de tentativas. Saliu usa o jogo de cara ou coroa (moeda) para explicar a aplicação da fórmula. As chances de cair cara ou coroa são de 50% para ambas. Suponha que se aposte na CARA. Na primeira tentativa o grau de certeza é de 50% para CARA. Já na décima tentativa, temos um grau de certeza de 99,9% para CARA. No nosso caso, nós temos os números de tentativas (Rodadas) e sabemos a probabilidade de se acertar 11, 12 ou 13 números na LotoFácil. Então, aplicamos a fórmula para obter o grau de certeza de um evento acontecer, ou seja, de obtermos o nosso objetivo, qual seja, acertar 11, 12 ou 13 números. Não estou criticando o autor do tópico e nem falando que o modo de jogo dele não funcione, apenas trago-lhes uma tabela demonstrando o grau de certeza para ganhar o jogo de azar, deixando as conclusões para cada um.

